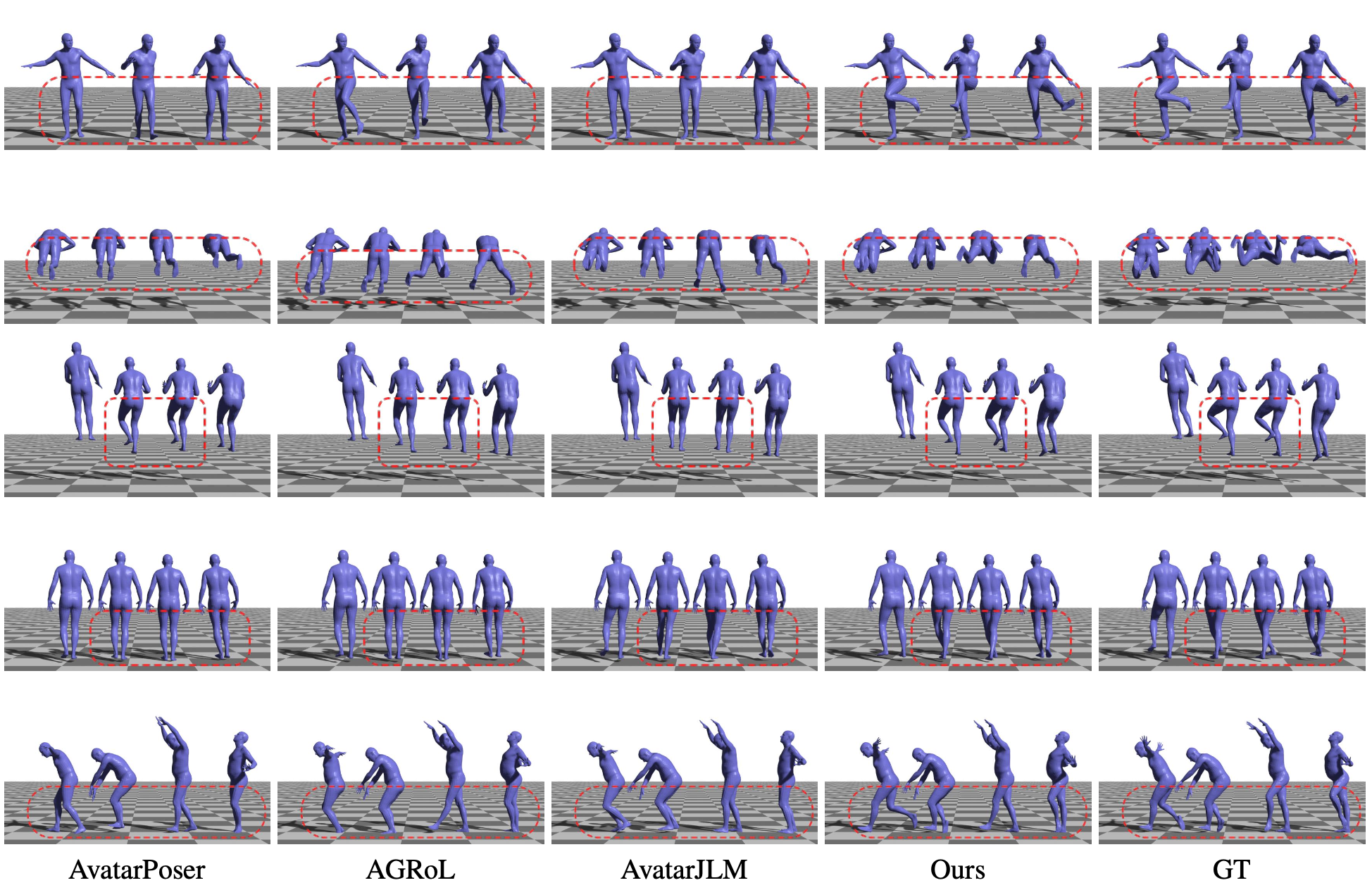
Approach
The proposed SAGE Net mainly contains two components: (a) Disentangled VQ-VAE for discrete human motion latent learning. To facilitate visualization, we incorporate zero rotations as padding for the lower body in the Upper VQ-VAE, and vice versa for the Lower VQ-VAE. Consequently, in the visualizations of the Upper VQ-VAE, the lower body remains in a stationary pose, whereas in the visualizations of the Lower VQ-VAE, the upper body is maintained in a T-pose. (b) The stratified diffusion model, which models the conditional distribution of the latent space for upper and lower motion. This model sequentially infers the upper and lower body latents, capturing the correlation between upper and lower motions. By employing a dedicated full-body decoder on the concatenated upper and lower latents, we can obtain full-body motion.